")
В этой статье мы расскажем о создании базового функционала сервиса транскрибации с применением FastAPI, Whisper и системы очередей обработки.
- Зачем нужна транскрибация звонков
- Общая схема работы
- Средства для транскрибации
- Пишем сервер API для взаимодействия
- Пример скрипта отправки запроса к серверу API
- Пишем обработчик очереди транскрибации
- Запускаем локальную модель LLM с использованием Ollama
- Добавляем диаризацию
- Пример скрипта отправки запроса к серверу API для диаризации текста
- Пишем обработчик очереди диаризации
- Вывод
Зачем нужна транскрибация звонков
В эпоху цифровизации и роста объёмов информации компании ищут эффективные способы работы с данными - в том числе с аудиозаписями телефонных разговоров. Один из ключевых инструментов в этом направлении - транскрибация звонков, то есть преобразование аудиозаписей разговоров в текстовый формат.
Почему транскрибация становится всё более востребованной? Ответ кроется в её многогранной пользе для бизнеса:
- Улучшение качества обслуживания клиентов. Анализ расшифровок помогает выявить сильные и слабые стороны взаимодействия с клиентами, скорректировать процессы и повысить их удовлетворённость.
- Обучение и развитие персонала. Записи звонков - ценный материал для обучения новых сотрудников: разбор успешных и неудачных кейсов совершенствует навыки продаж и поддержки.
- Соблюдение нормативных требований. В ряде отраслей (например, в финансах и юриспруденции) компании обязаны фиксировать переговоры. Текстовая расшифровка упрощает хранение и предоставление данных при проверках и аудите.
- Глубокий анализ данных. Текстовый формат позволяет быстро искать ключевые слова и фразы, выявлять часто задаваемые вопросы, анализировать настроения клиентов и формировать отчётность.
- Упрощение внутренней коммуникации. Транскрибированные разговоры легко передавать коллегам - это экономит время и помогает синхронизировать команду, особенно если кто‑то пропустил звонок.
- Оптимизация бизнес‑процессов. Понимание потребностей и реакций клиентов помогает адаптировать стратегии, улучшать продукты и услуги, предлагать более релевантные решения.
- Доступность информации. Текст удобен для людей с нарушениями слуха, а также для тех, кому проще воспринимать информацию визуально.
- Предотвращение споров. Отправка транскрибации клиенту после разговора фиксирует договорённости и снижает риск разночтений.
Развитие искусственного интеллекта и появление удобных сервисов автоматической транскрибации сделали эту технологию доступной не только крупным корпорациям, но и малому бизнесу. Сегодня различные инструменты позволяют быстро и точно получать текстовые версии разговоров - и использовать их для роста эффективности.
В этой статье мы подробно разберём, как создать свой сервис транскрибации и диаризации звонков, работающий локально без отправки данных в облако. Данная статья написана из реального опыта разработки такого сервиса, заказанного одним из наших клиентов. Опуская детали, которые могли бы коснуться этого клиента, расскажем о ключевых моментах разработки.
Общая схема работы сервиса транскрибации
Что мы имеем в начале: таблицу с данными звонка:
- входящий/исходящий
- номер звонившего
- номер куда звонили
- дата начала разговора
- дата окончания разговора
- ссылка на файл с записью разговора
Общая схема работы сервиса выглядит так:
- система абонента делает выборку какой-то порции звонков из таблицы звонков в базе данных, передает эти данные серверу API
- сервер API принимает эти данные, сохраняет файл разговора с уникальным идентификатором у себя, возвращает этот уникальный идентификатор в ответе на запрос, ставит файл в очередь на обработку
- обработчик очереди транскрибации проверяет очередь, берет очередной файл и транскрибирует его, текстовые данные из разговора помещаются в очередь расшифрованных звонков вместе с уникальным идентификатором в сервисе транскрибации
- система абонента периодически запрашивает результат готовности транскрибации, используя уникальный идентификатор полученный выше, если транскрибирование выполнено - сервер API отдает текстовую расшифровку
- система абонента при получении текстовой расшифровки сохраняет ее в базе данных и шлет запрос на удаление из стека расшифрованных звонков полученного в предыдущем шаге звонка, используя уникальный идентификатор в сервисе транскрибации
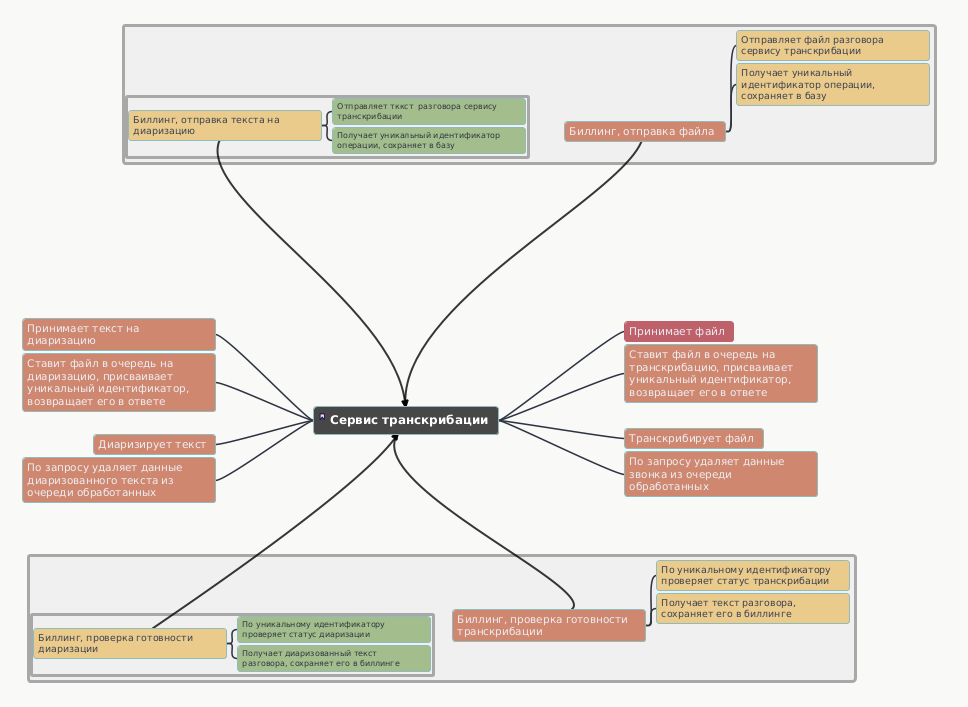
параллельно с этим выполняется еще одно действие - диаризация расшифрованного разговора:
- система абонента выбирает необработанные разговоры, к которым уже получена текстовая расшифровка, передает эти данные серверу API
- сервер API принимает эти данные, сохраняет текст разговора с уникальным идентификатором у себя, возвращает этот уникальный идентификатор в ответе на запрос, ставит файл в очередь на диаризацию
- обработчик очереди диаризации проверяет очередь, берет очередной файл и выполняет обработку, текстовые данные из разговора помещаются в очередь вместе с уникальным идентификатором в сервисе транскрибации
- система абонента периодически запрашивает результат готовности диаризации, используя уникальный идентификатор полученный выше, если обработка выполнена - сервис отдает размеченный текст
- система абонента при получении данных диаризации сохраняет текст в базе данных и шлет запрос на удаление из очереди обработанных текстов полученного в предыдущем шаге текста, используя уникальный идентификатор в сервисе транскрибации
Средства для транскрибации
Для транскрибации звонков сейчас есть много инструментов - и выбор сильно зависит от того, что именно вам нужно: просто быстро получить текст, глубоко проанализировать диалог или встроить расшифровку в рабочие процессы.
Есть 3 способа перевода аудио в текст: ручной, автоматизированный и гибридный
- Ручной способ. Специалист слушает запись и набирает текст. Это самый точный метод, но он требует времени и ресурсов.
- Автоматический режим. С развитием ИИ начал получать массовое применение. В этом способе используются система распознавания для автоматического перевода диалога в текст.
- Гибридный. ИИ расшифровывает аудиозапись, после чего оператор читает и корректирует ошибки.
В нашем решении используется автоматический режим, поэтому разберем средства для его реализации более подробно. Вот несколько инструментов, позволяющих выполнять расшифровку в автоматическом режиме:
mymeet.ai. Хорош для деловых звонков и встреч. Может подключаться как бот к Zoom, Google Meet, Microsoft Teams или Яндекс.Телемосту (через интеграцию с календарём). Разделяет реплики по спикерам, ставит таймкоды, позволяет задавать вопросы по содержанию архива и формировать краткие резюме. Есть бесплатный лимит (180 минут), данные хранятся в России.
Otter.ai. Отлично подходит для виртуальных встреч (Zoom, Google Meet, Teams) - транскрибирует в реальном времени. Умеет разделять спикеров, делать заметки прямо в тексте, экспортировать в DOCX,
PDF, SRT. Слабее работает с русской речью.
Яндекс SpeechKit. Мощный вариант для русской речи. Это API-сервис - его чаще встраивают в корпоративные системы, а не используют через готовый веб-интерфейс для разовой загрузки файла. Поддерживает потоковое распознавание и пакетную обработку.
Speech2Text. Российский сервис с фокусом на разделение спикеров и онлайн-редактирование транскрипта.
Any2Text. Ориентирован на простоту: можно загрузить файл или вставить ссылку (например, на запись встречи). Сам определяет язык, поддерживает много форматов, экспортирует в DOCX, TXT, SRT.
Whisper (от OpenAI). Нейросеть с открытым исходным кодом. Одна из сильных сторон - хорошая точность, в том числе на записях с шумами или акцентами. Можно развернуть локально (что важно для вопросов безопасности данных), но для этого нужны технические навыки (Python, командная строка). Не всегда идеально разделяет спикеров и не всегда отлично справляется с русской речью - часто требуется ручная доработка.
Рассмотрев различные способы транскрибации, было решено взять за основу инструмент Whisper - это бесплатная модель ИИ, которая позволяет перегонять аудио в текст. Имеет хорошую масштабируемость, работает как на CPU так и на GPU, не требует подключения интернета - работает полностью локально.
Все скрипты к данной статье написаны на Python, поэтому для начала установим все необходимые модули.
Устанавливаем модуль Whisper для Python:
pip install openai-whisper
Когда модуль будет установлен, можно переходить к разработке сервиса.
Пишем сервер API для взаимодействия
Главная задача сервиса для взаимодействия - принимать запросы и ставить их в очередь на обработку, при запросе статуса транскрибации - возвращать текущее состояние, и при запросе на удаление готовых результатов из очереди - выполнять удаление.
Для разработки сервиса будем использовать FastAPI. Установим необходимые пакеты для питона:
pip install fastapi python-multipart
У сервера API будет 4 конечный точки:
- / - запрос без параметров, просто для теста и понимания что сервис в рабочем состоянии
- /transcribe - добавление файла в очередь на транскрибирование
- /transcribe_result - получение статуса транскрибирования файла в очереди
- /transcribe_clear_result - удаление файла из очереди
Так как этот сервис призван продемонстрировать работу всех системы, он будет максимально упрощен - файл аудиозвонка будет передаваться в переменной filedata, ему будет присваиваться уникальное имя сгенерированное в виде UUIDv4 и сохраняться в папку очереди queue, имя файла будет возвращаться в ответе на запрос (transcribe). При запросе статуса нужно будет проверить, есть ли файл с расшифрованным разговором в папке completed - туда будут сохраняться сами обработанные файлы + их текстовые описания в формате json. Если файл есть - значит он обработан и можно отдать данные расшифровки разговора (transcribe_result). После того, как расшифровка получена - файл можно удалить из очереди (чтобы не засорять пространство), для этого послужит метод transcribe_clear_result.
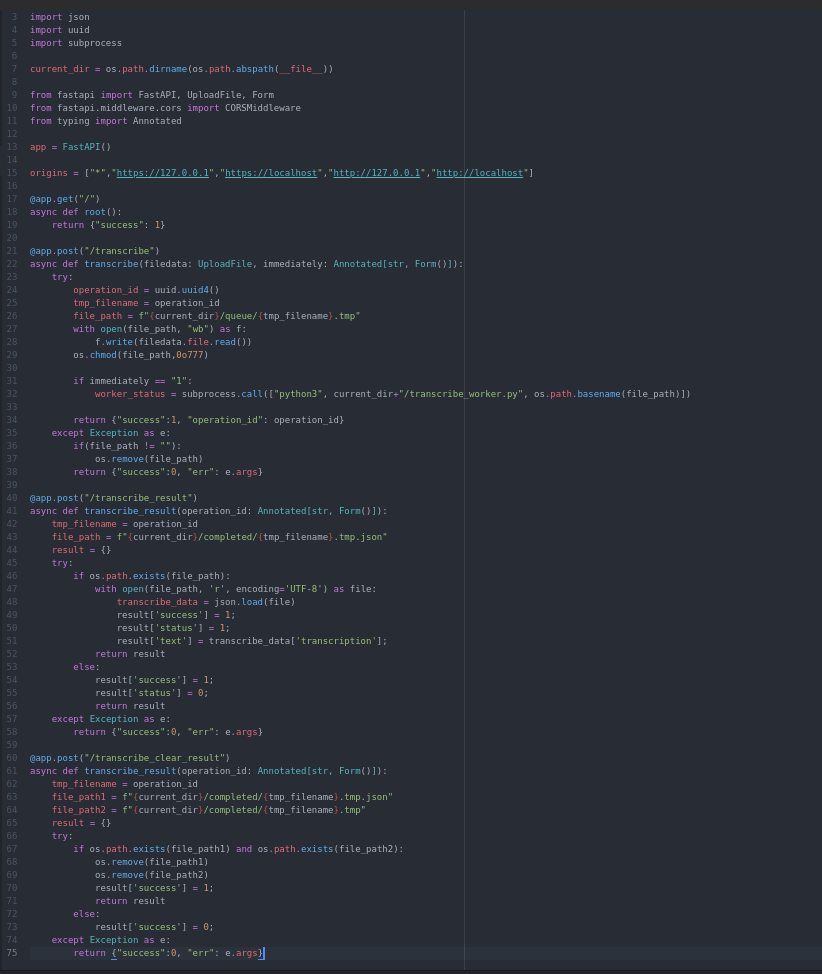
Пример скрипта отправки запроса к серверу API

Пишем обработчик очереди транскрибации
Итак, теперь у нас есть сервер API для взаимодействия, он умеет ставить файлы в очередь на расшифровку, проверять статус расшифровки и удалять файл из очереди. Так же мы умеем отправлять ему запросы. Теперь нужно написать сам скрипт, который будет реализовывать обработку очереди - брать файл из очереди, транскрибировать его и записывать результат в файл, помечая аудиозапись как обработанную.
Создадим небольшой модуль, который будет обеспечивать взаимодействие с нейросетью и выполнять расшифровку аудио LocalTranscriber.py
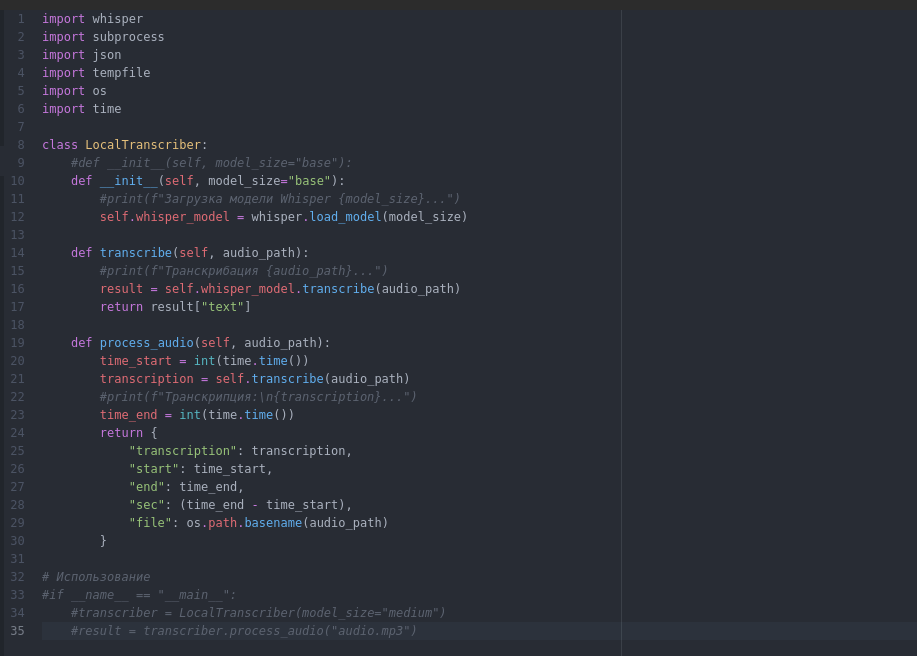
В примере используется размер модели base, но у Whisper большой выбор других моделей, подходящих под разные вычислительные мощности серверов (чем больше модель, тем она точнее):
Размеры моделей Whisper
По количеству параметров:
- tiny - 39 миллионов параметров
- base - 74 миллиона параметров
- small - 244 миллиона параметров
- medium - 769 миллионов параметров
- large - 1,55 миллиарда параметров (самая точная версия)
Дополнительные модели:
- turbo - 809 миллионов параметров, дистиллированная версия large-v3, которая обеспечивает высокую скорость работы при почти такой же точности, как у large-v3
Версии large:
- large-v1 - оригинальная версия
- large-v2 - обученная на 2,5 раза больше эпох с добавлением регуляризации
- large-v3 - обученная на большем объёме данных с использованием 128 бинов Mel-частот вместо 80.
Во избежание дубликатов запуска скрипта добавим создание lock - файла при запуске и удалением в конце работы, с помощью которого будет блокироваться запуск других экземпляров скрипта.
Пишем скрипт - обработчик очереди:
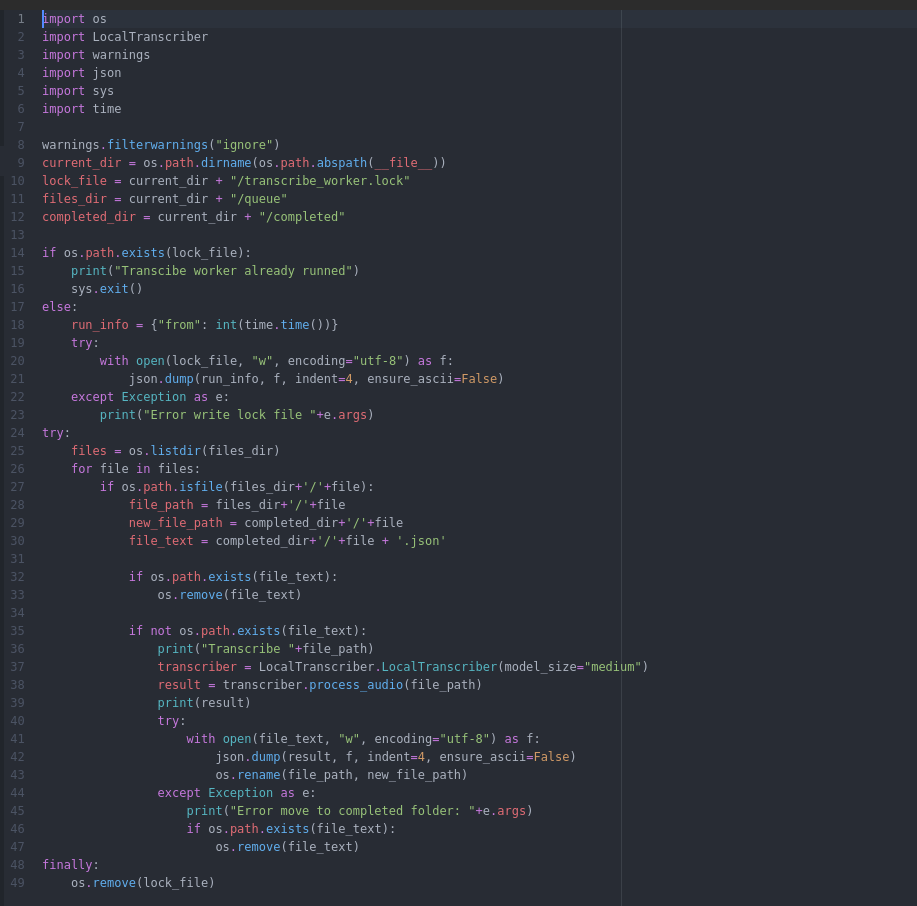
Обработчик при запуске читает каталог с файлами - аудиозаписями разговоров, по очереди передает имя файла в LocalTranscriber, получает от него данные с расшифровкой, записывает полученные данные в файл совпадающий именем с файлом аудиозаписи и расширением я json, в каталог отработанных файлов очереди (completed) и туда - же переносит сам файл аудиозаписи. После того, как все файлы в каталоге будут расшифрованы - скрипт удаляет файл блокировки запуска и завершает работу. Таким образом обеспечивается функционал расшифровки разговоров через API. Решение является демонстрационным, рабочая версия может выглядеть значительно сложнее - например можно добавить опцию реалтайм - расшифровки, то есть минуя очередь. Для этого можно добавить специальный флаг, который будет передаваться серверу API вместе с файлом аудиозаписи. В случае установки такого флага сервер должен будет сразу же запустить отдельный экземпляр обработчика, получить от него ответ и вернуть результат. В нашей версии так и было реализовано, но в этой статье я не буду рассматривать это решение, там нет ничего сложного - передать скрипту в аргументе имя файла для обработки, добавить в проверку блокировки запуска условие на то, что он запускается с передачей имени файла - в этом случае блокировку игнорировать (и не удалять его в конце !).
Теперь у нас есть текстовая расшифровка разговора, но она не очень удобна для прочтения, так как идет сплошным текстом. Для более удобного чтения текст нужно диаризовать.
«Диаризация» - это технический термин, который означает процесс автоматической разметки аудио- или видеозаписи, чтобы определить, кто и когда говорил. Проще говоря, это разметка по спикерам: система анализирует голос и присваивает каждому участнику беседы временную метку («Спикер 1», «Спикер 2» и т. д.) с указанием, какие реплики ему принадлежат.
Чтобы диаризовать наш текст, потребуется установка и запуск движка Ollama для локального запуска LLM.
LLM (Large Language Model - большая языковая модель) - это тип искусственного интеллекта, который обучен работать с текстом: понимать, генерировать, пересказывать, дополнять, переводить и анализировать его. Такие модели анализируют взаимосвязи между словами, темами и ситуациями, что позволяет им выполнять задачи, которые раньше требовали участия человека.
Запускаем локальную модель LLM с использованием Ollama
Ollama - это программная платформа с открытым исходным кодом (распространяется под лицензией MIT), предназначенная для локального запуска и управления большими языковыми моделями (LLM - Large Language Models). Инструмент упрощает работу с ИИ‑моделями: вместо сложной настройки окружения и решения проблем совместимости достаточно выполнить несколько команд в терминале - и вы уже можете взаимодействовать с мощной языковой моделью прямо на своём устройстве.
Ключевые возможности
- Локальное выполнение. Модели работают на вашем компьютере или сервере - без передачи данных в облако. Это обеспечивает повышенный уровень конфиденциальности и контроля над информацией.
- Простой интерфейс. Платформа предоставляет командную строку (CLI) для загрузки, запуска, настройки и удаления моделей.
- Унифицированный API. В основе Ollama лежит локальный веб‑сервер с JSON REST API - это позволяет интегрировать языковые модели в собственные приложения и сервисы.
- Поддержка разных моделей. Через Ollama можно запускать множество популярных LLM, включая LLaMA, Mistral, CodeLlama и другие.
- Гибкость развёртывания. Платформа совместима с основными операционными системами (Windows, macOS, Linux) и поддерживает запуск в Docker‑контейнерах.
Как установить Ollama на ПК и запустить локально LLM ?
Рассмотрим способ установки под Linux (под другие ОС он практически не отличается).
- Выполните в терминале: curl -fsSL https://ollama.com/install.sh | sh. Иногда не хватает пакетов curl или zstd (для Debian/Ubuntu: sudo apt update && sudo apt install curl zstd). После установки может потребоваться запустить службу: sudo systemctl start ollama
- Скачайте подходящую под ваши задачи и системные требования модель - выбрать можно на сайте Ollama.com (https://ollama.com/search), скачать командой Ollama pull ==имя модели==.
Например ollama pull gemma4:e2b - запустите модель ollama run gemma4:e2b
Все ! На этом базовая настройка Ollama завершена. Теперь для диаризации нам нужно добавить новые конечные точки в API нашего сервиса, которые бы принимали и ставили в очередь текст на диаризацию, отслеживали статус диаризации и удаляли из очереди отработанные тексты. Все как с транскрибацией, только тут мы передаем не файл, а уже текст, и обработчик для очереди диаризации у нас будет отдельный.
Добавляем диаризацию
Добавляем 3 конечных точки в сервер API, для реализации функций диаризации:
- /transcribe_decoder - поместить текст в очередь
- /transcribe_decoder_result - получить статус текста
- /transcribe_decoder_clear_result - удалить ntrcn из очереди обработанных текстов
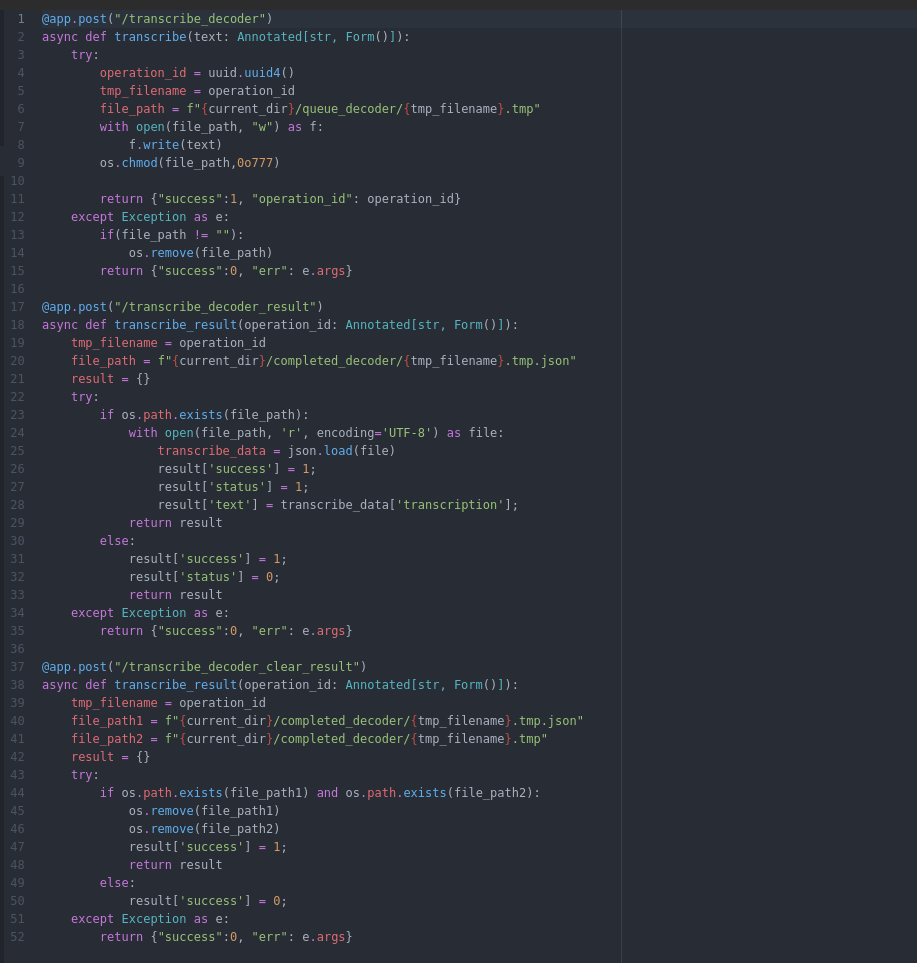
Пример скрипта отправки запроса к серверу API для диаризации текста
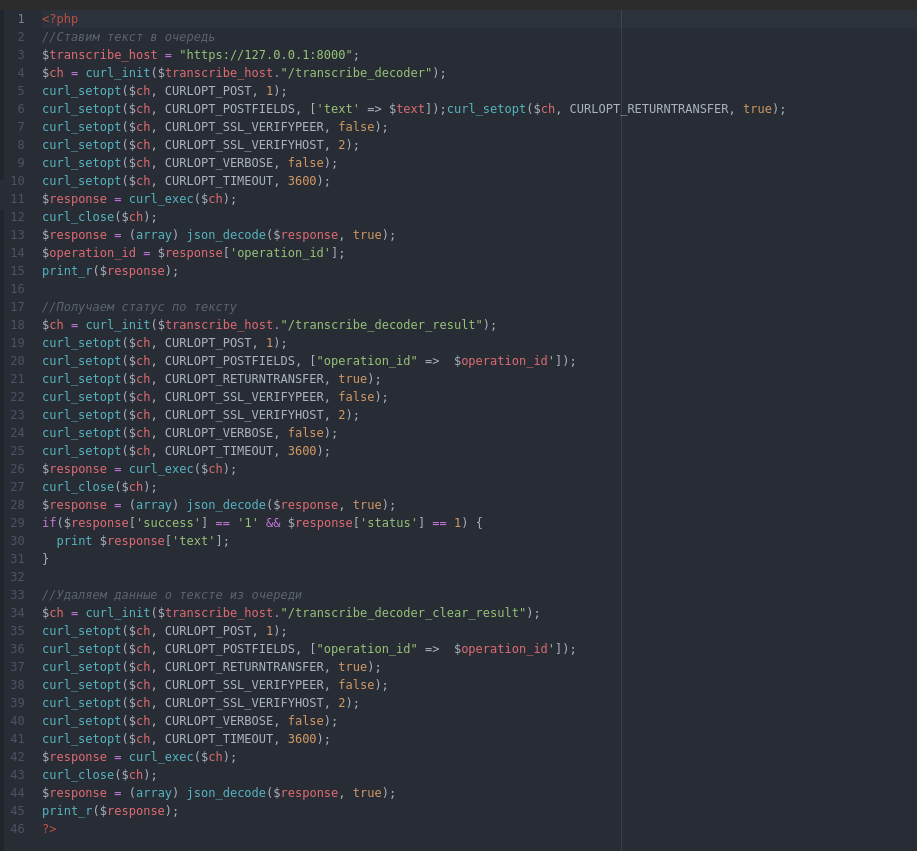
Пишем обработчик очереди диаризации
Наш скрипт обработки очереди диаризации должен запуститься по расписанию (используем для этого крон), проверить, не запущен ли уже экземпляр скрипта диаризации - если не запущен - перебрать файлы в каталоге очереди и с помощью запроса к Ollama произвести диаризацию. Результат работы записать в каталог готовых файлов очереди, перенести туда - же исходный файл с текстом из каталога очереди.
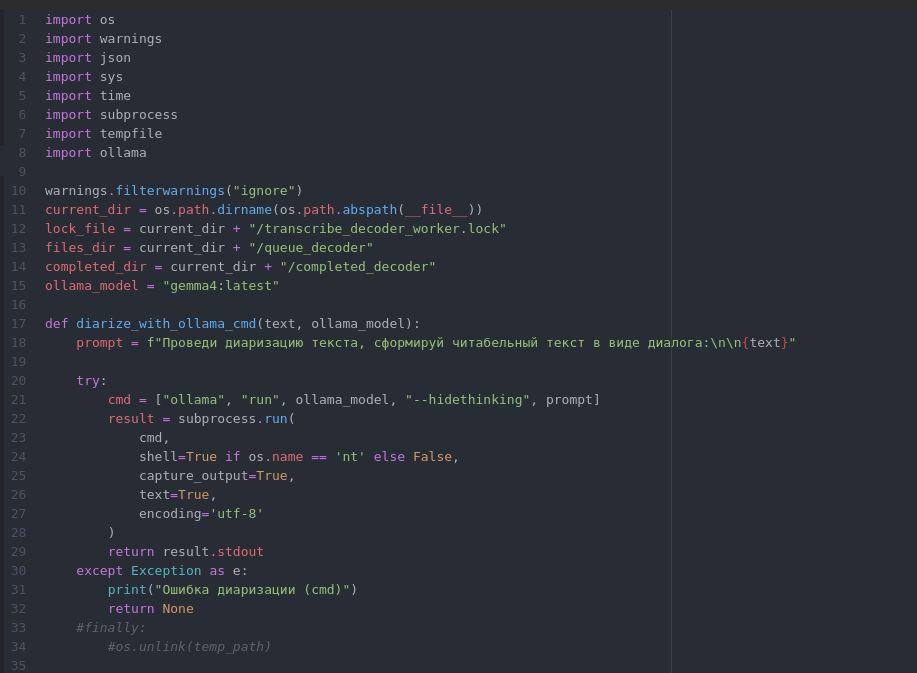
Вывод
В результате проделанной работы мы создали комплексное решение для автоматической обработки аудиозаписей телефонных разговоров, включающее в себя:
- Локальный сервис транскрибации на базе модели Whisper, способный работать без доступа к интернету
- Систему диаризации с использованием современных LLM-моделей через платформу Ollama
- сервер API для взаимодействия с системой
- Механизм очередей для обработки файлов
Основные достижения проекта:
- Разработана архитектура, обеспечивающая безопасность данных благодаря локальному размещению
- Реализована гибкая система с возможностью выбора размера модели Whisper под конкретные задачи
- Создан удобный интерфейс для интеграции с существующими системами
- Внедрена двухэтапная обработка: сначала транскрибация, затем диаризация
Практическая значимость решения:
- Автоматизация бизнес-процессов за счет быстрого преобразования аудио в текст
- Улучшение качества обслуживания через анализ разговоров
- Оптимизация работы персонала благодаря возможности обучения на реальных кейсах
- Соответствие требованиям безопасности при работе с конфиденциальной информацией
Перспективы развития:
- Внедрение дополнительных моделей для повышения точности распознавания
- Оптимизация производительности системы
- Добавление функционала анализа тональности речи
- Интеграция с системами CRM и бизнес-аналитики
Данное решение может быть успешно применено в различных сферах бизнеса, где требуется работа с большими объемами аудиоинформации, при этом важно соблюдение требований по безопасности и конфиденциальности данных.
Разработанный подход демонстрирует, как современные технологии искусственного интеллекта могут быть эффективно использованы для решения практических задач бизнеса, при этом оставаясь в рамках локальных инфраструктур и обеспечивая необходимый уровень защиты информации.
Рекомендуем прочитать






Хотите внедрить подобное решение или автоматизировать другие бизнес‑процессы с помощью современных технологий? Доверьте разработку индивидуальных технических решений нашей Digital‑студии Bleaksoft!
Мы создаём:
- сервисы транскрибации и диаризации с учётом ваших задач;
- локальные ИИ‑решения без передачи данных в облако;
- API‑интеграции с существующими системами (CRM, BI и др.);
- кастомные инструменты на базе LLM и нейросетей;
- автоматизированные системы обработки аудио‑, видео‑ и текстовых данных.
Почему Bleaksoft:
- Безопасность. Разрабатываем решения для работы в закрытой инфраструктуре - ваши данные остаются под вашим контролем.
- Гибкость. Масштабируемые архитектуры под текущий объём задач и перспективы роста.
- Экспертиза. Опыт внедрения ИИ‑инструментов в реальных бизнес‑сценариях.
- Полный цикл. От проектирования и разработки до внедрения, тестирования и поддержки.
Оптимизируйте бизнес‑процессы уже сегодня: сократите время на обработку данных, повысьте качество аналитики и сосредоточьтесь на стратегически важных задачах.
Свяжитесь с нами, чтобы обсудить ваш проект - мы предложим оптимальное техническое решение и рассчитаем сроки реализации!
Отправьте заявку на разработку / сопровождение сайта
Мы вам перезвоним.

